This post first describes competitive learning algorithms, and then goes on to discuss the web application I made to graphically simulate them. You can check out the web application right here and have a play.
Competitive Learning Algorithms
Competitive learning algorithms are a class of unsupervised learning algorithm. The general aim across all of these algorithms is pretty much the same (though the actual steps employed in individual algorithms to do this varies a fair bit). Basically, the problem is this: You are given, in sequence, a list (with an unknown and possibly infinite length) of positions, known as inputs. From this sequence of inputs, the goal is to build up a description of the inputs, such that you can estimate from which positions inputs are more or less likely to come from in the future. In order to do this, algorithms seek to position nodes throughout the space in which these inputs occur. The positions of these nodes are incrementally adjusted as more and more inputs are seen. The aim of each algorithm is to position these nodes as best as possible in order to represent the underlying inputs.
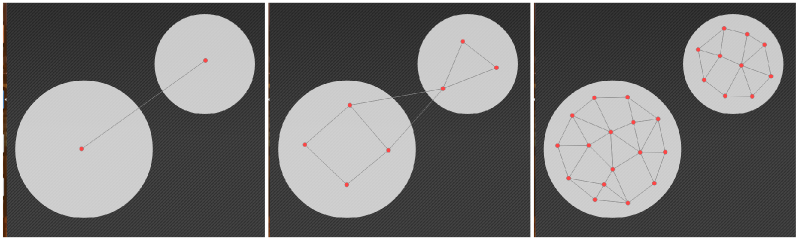
This representation of the inputs can be used for a variety of purposes. For example, in the case where inputs are seen in several distinct regions, the nodes representing them can be used to classify them accordingly. Along similar lines, a potentially infinite number of different input positions can be represented in terms of a small number of nodes. This is known as discretization; turning a continuous set of inputs into a discrete number of outputs, and is useful for things like data compression. In either case, how the algorithm decides on where nodes will be placed is of great importance; the accuracy with which the nodes represent the input space determines the accuracy of the classification or discretization.
The algorithms are known as competitive because the different nodes generated by them compete with each-other to represent different regions of inputs. Each time an input is seen, the algorithms generally work by finding the closest node to that input, and then moving that node a little closer to it. As a result, each node will come to be closest to a certain region in which inputs occur, and will therefore be selected every time an input from this region occurs again. The selected node is said to be the winning node. Soft competitive algorithms take this a little further, and move not just the closest node but those nodes connected to it towards an input each time one is seen. This helps ensure that nodes are spread more evenly across regions in which inputs tend to occur, rather than one node representing a large region of inputs all by itself; a problem exacerbated when the algorithm needs to learn about a constantly changing input space.
The Application
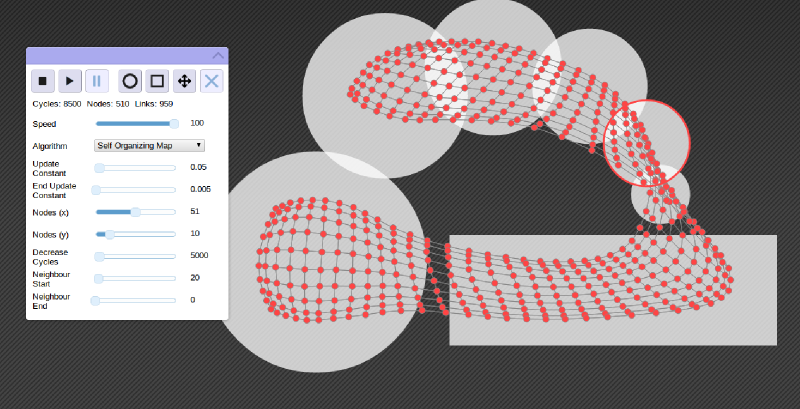
Enhancing these algorithms for a particular robot learning scenario was the central part of my Ph.D. One of the most useful tools I found along the way was a Java application which showed graphically how several of these algorithms actually worked. However, in that application you were unable to manipulate where inputs come from yourself, or make any real-time changes to parameters to see how they affect performance.
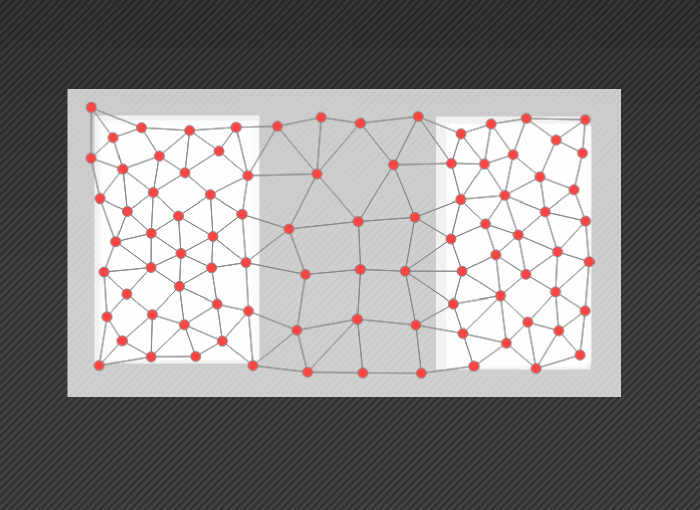
So, the first thing I did when I learnt to use Javascript is to write my own application designed to allow people to play with a few competitive learning algorithms. In this application, the user can draw shapes which dictate where inputs come from. On pressing the play button, the currently selected algorithm will be fed inputs based on where the shapes are drawn, one at a time, and will move the nodes under its control in an attempt to represent this user created input space. In effect, the successful algorithm will spread nodes throughout the drawn shapes.
Taking this one step further, the user can modify parameters, draw new shapes, move shapes, and erase shapes, all while the simulation is running. This is particularly handy for seeing how well the algorithms (and the given parameters) can adapt to changes in the input space. Some algorithms (Growing Neural Gas) are much better than others (the Self Organizing Map) at this adaptation over time; something which was critical to me during my Ph.D work.
The application involves three main layers:
- The input generator layer.
- The algorithm layer.
- The interface layer.
The input generator layer is told about the size and position of shapes. It can draw the shapes it knows about to a canvas, and it can generate inputs which are randomly distributed throughout the shapes.
The algorithm layer is told which algorithm to use, and depending on the algorithm provides an interface to change the relevant parameters. It can be fed input positions, at which point it adjusts nodes accordingly. It also provides functionality to draw nodes and any links between them to a canvas for visualization. It was made to work in any number of dimensions, however for the purpose of this application is only makes use of 2.
The interface layer involves all of the code which drives the interface, and feeds user input in to the algorithm and input generating layers. It relies heavily on the jQuery framework to simplify interactions with the DOM and provide a few animations (such as when minimising the interface box or changing the algorithm used).
For simplicity, each layer actually draws to a physically different canvas, resulting in three canvases layered on top of each-other. This makes it easy to do things like redraw the shape layer when shaped are added, removed or deleted without redrawing the nodes and links, and ensuring that the shape outlines provided when manipulating them always occur on top.
Final Thoughts
Looking back with more experience, there are several things I'd change, but all in all it was an interesting display of what Javascript is actually capable of; the whole simulation runs far smoother than I had ever expected, even wih a large number of nodes running at 100 times its actual speed. The simulator can run at far greater speeds than this, however 100x seemed plenty fast enough for any simulation purposes.
For anyone interested in learning about competitive learning algorithms, this simulator is a great way to get a feel for what's actually going on. If you haven't already, check it out here. If you have any comments or questions, feel free to post them below!